
Representational Similarity Analysis- A great method for linking ERPs to computational models, fMRI data, and more
/Representational similarity analysis (RSA) is a powerful multivariate pattern analysis method that is widely used in fMRI, and my lab has recently published two papers applying RSA to ERPs. We’re not the first researchers to apply RSA to ERP or MEG data (see, e.g., Cichy & Pantazis, 2017; Greene & Hansen, 2018). However, RSA is a relatively new approach with amazing potential, and I hope this blog inspires more people to apply RSA to ERP data. You can also watch a 7-minute video overview of RSA on YouTube. Here are the new papers:
Kiat, J.E., Hayes, T.R., Henderson, J.M., Luck, S.J. (in press). Rapid extraction of the spatial distribution of physical saliency and semantic informativeness from natural scenes in the human brain. The Journal of Neuroscience. https://doi.org/10.1523/JNEUROSCI.0602-21.2021 [preprint] [code and data]
He, T., Kiat, J. E., Boudewyn, M. A., Segae, K., & Luck, S. J. (in press). Neural Correlates of Word Representation Vectors in Natural Language Processing Models: Evidence from Representational Similarity Analysis of Event-Related Brain Potentials. Psychophysiology. https://doi.org/10.1111/psyp.13976 [preprint] [code and data]
Examples
Before describing how RSA works, I want to whet your appetite by showing some of our recent results. Figure 1A shows results from a study that examined the relationship between scalp ERP data and a computational model that predicts the saliency of each location in a natural scene. 50 different scenes were used in the experiment, and the waveform in Figure 1A shows the representational link between the ERP data and the computational model at each moment in time. You can see that the link onsets rapidly and peaks before 100 ms, which makes sense given that the model is designed to reflect early visual cortex. Interestingly, the link persists well past 300 ms. Our study also examined meaning maps, which quantify the amount of meaningful information at each point in a scene. We found that the link between the ERPs and the meaning maps began only slightly after the link with the saliency model. You can read more about this study here.
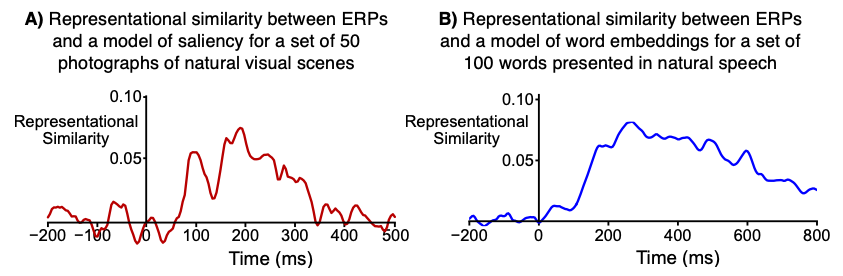
FIGURE 1
Figure 1B shows some of the data from our new study of natural language processing, in which subjects simply listened to stories while the EEG was recorded. The waveform shows the representational link between scalp ERP data and a natural language processing model for a set of 100 different words. You can see that the link starts well before 200 ms and lasts for several hundred milliseconds. The study also examined a different computational model, and it contains many additional interesting analyses.
In these examples, RSA allows us to see how brain activity elicited by complex, natural stimuli can be related to computational models, using brain activity measured with the high temporal resolution and low cost of scalp ERP data. This technique is having a huge impact on the kinds of questions my lab is now asking. Specifically :
RSA is helping us move from simple, artificial laboratory stimuli to stimuli that more closely match the real world.
RSA is helping us move from qualitative differences between experimental conditions to quantitative links to computational models.
RSA is helping us link ERPs with the precise neuroanatomy of fMRI and with rich behavioral datasets (e.g., eye tracking).
Figure 1 shows only a small slice of the results from our new studies, but I hope they give you the idea of the kinds of things that are possible with RSA. We’ve also made the code and data available for both the language study (https://osf.io/zft6e/) and the visual attention study (https://osf.io/zg7ue/). Some coding is skill is necessary to implement RSA, but it’s easier than you might think (especially when you use our code and code provided by other labs as a starting point).
Now let’s take a look at how RSA works in general and how it is applied to ERP data.
The Essence of Representational Similarity Analysis (RSA)
RSA is a general-purpose method for assessing links among different kinds of neural measures, computational models, and behavior. Each of these sources of data has a different format, which makes them difficult to compare directly. As illustrated in Figure 2, ERP datasets contain a voltage value at each of several scalp electrode sites at each of several time points; a computational model might contain an activation value for each of several processing units; a behavioral dataset might consist of a set of eye movement locations; and an fMRI dataset might consist of a set of BOLD beta values in each voxel within a given brain area. How can we link these different types of data to each other? The mapping might be complex and nonlinear, and there might be thousands of individual variables within a dataset, which would limit the applicability of traditional approaches to examining correlations between datasets.
RSA takes a very different approach. Instead of directly examining correlations between datasets, RSA converts each data source into a more abstract but directly comparable format called a representational similarity matrix (RSM). To obtain an RSM, you take a large set of stimuli and use these stimuli as the inputs to multiple different data-generating systems. For example, the studies shown in Figure 1 involved taking a set of 50 visual scenes or 100 spoken words and presenting them as the input to a set of human subjects in an ERP experiment and as the input to a computational model.
As illustrated in Figure 2A, each of the N stimuli gives you a set of ERP waveforms. For each pair of the N stimuli, you can quantify the similarity of the ERPs (e.g., the correlation between the scalp distributions at given time point), leading to an N x N representational similarity matrix.

FIGURE 2
The same N stimuli would also be used as the inputs to the computational model. For each pair of stimuli, you can quantify the similarity of model’s response to the two stimuli (e.g., the correlation between the pattern of activation produced by the two stimuli). This gives you an N x N representational similarity matrix for the model.
Now we’ve transformed both the ERP data and the model results into N x N representational similarity matrices. The ERP data and the model originally had completely different units of measurement and data structures that were difficult to relate to each other, but now we have the same data format for both the ERPs and the model. This makes it simple to ask how well the similarity matrix for the ERP data matches the similarity matrix for the model. Specifically, we can just calculate the correlation between the two matrices (typically using a rank order approach so that we only assume a monotonic relationship, not a linear relationship).
Some Details
The data shown in Figure 1 used the Pearson r correlation coefficient to quantify the similarity between ERP scalp distributions. We have found that this is a good metric of similarity for ERPs, but other metrics can sometimes be advantagous. Note that many researchers prefer to quantify dissimilarity (distance) rather than similarity, but the principle is the same.
Each representational similarity matrix (RSM) captures the representational geometry of the system that produced the data (e.g., the human brain or the computational model). The lower and upper triangles of the RSM as described in this approach are mirror images of each other and are redundant. Similarly, cells along the diagonal index the similarity of each item to itself and are not considered in cross-RSM comparisons. We therefore use only the lower triangles of the RSMs. As illustrated in Figure 2a, the representational similarity between the ERP data and the computational model is simply the (rank order) correlation between the values in these two lower triangles.
When RSA is used with ERP data, representational similarity is typically calculated separately for each time point. That is, the scalp distribution is obtained at a given time point for each of the N stimuli, and the correlation between the scalp distributions for each pair of stimuli is computed at this time point. Thus, we have an N x N RSM at each time point for the ERP data. Each of these RSMs is then correlated with the RSM from the computational model. If the model has multiple layers, this process is conducted separately for each layer.
For example, the waveforms shown in Figure 1 show the (rank order) correlation between the ERP RSM at a given time point and the model RSM. That is, each time point in the waveform shows the correlation between the ERP RSM for that time point and the model RSM.
ERP scalp distributions can vary widely across people, so RSA is conducted separately for each participant. That is, we compute an ERP RSM for each participant (at each time point) and calculate the correlation between that RSM and the Model RSM. This gives us a separate ERP-Model correlation value for each participant at each time point. The waveforms shown in Figure 1 show the average of the single-participant correlations.
The correlation values in RSA studies of ERPs are typically quite low compared to the correlation values you might see in other contexts (e.g., the correlation between P3 latency and response time). For example, all of the correlation values in the waveforms shown in Figure 1 are less than 0.10. However, this is not usually a problem for the following reasons:
The low correlations are mainly a result of the noisiness of scalp ERP data when you compute a separate ERP for each of 50-100 stimuli, not a weak link between the brain and the model.
It is possible to calculate a “noise ceiling,” which represents the highest correlation between RSMs that could be expected given the noise in the data. The waveforms shown in Figure 1 reach a reasonably high value relative to the noise ceiling.
When the correlation between the ERP RSM and the model RSM is computed for a given participant, the number of data points contributing to the correlation is typically huge. For a 50 x 50 RSM (as in Figure 1A), there are 1225 cells in the lower triangle. 1225 values from the ERP RSM are being correlated with 1225 values from the model RSM. This leads to very robust correlation estimates.
Additional power is achieved from the fact that a separate correlation is computed for each participant.
In practice, the small correlation values obtained in ERP RSA studies are scientifically meaningful and can have substantial statistical power.
RSA is usually applied to averaged ERP waveforms, not single-trial data. For example, we used averages of 32 trials per image in the experiment shown in Figure 1A. The data shown in Figure 1B are from averages of at least 10 trials per word. Single-trial analyses are possible but are much noisier. For example, we conducted single-trial analyses of the words and found statistically significant but much weaker representational similarity.
Other Types of Data
As illustrated in Figure 2A, RSA can also be used to link ERPs to other types of data, including behavioral data and fMRI data.
The behavioral example in Figure 2A involves eye tracking. If the eyes are tracked while participants view scenes, a fixation density map can be constructed showing the likelihood that each location was fixated for each scene. An RSM for the eye-tracking data could be constructed to indicate the similarity between fixation density maps for each pair of scenes. This RSM could then be correlated with the ERP RSM at each time point. Or the fixation density RSMs could be correlated with the RSM for a computational model (as in a recent study in which we examined the relationship between infant eye movement patterns and a convolutional neural network model of the visual system; Kiat et al., 2022).
Other types of behavioral data could also be used. For example, if participants made a button-press response to each stimulus, one could use the mean response times for each stimulus to construct an RSM. The similarity value for a given cell would be the difference in mean RT between two different stimuli.
RSA can also be used to link ERP data to fMRI data, a process called data fusion (see, e.g., Mohsenzadeh et al., 2019). The data fusion process makes it possible to combine the spatial resolution of fMRI with the temporal resolution of ERPs. It can yield a millisecond-by-millisecond estimate of activity corresponding to a given brain region, and it can also yield a voxel-by-voxel map of the activity corresponding to a given time point. More details are provided in our YouTube video on RSA.