How Many Trials Should You Include in Your ERP Experiment?
/One question we often get asked at ERP Boot Camps is how many trials should be included in an experiment to obtain a stable and reliable version of a given ERP component. It turns out there is no single answer to this question that can be applied across all ERP studies.
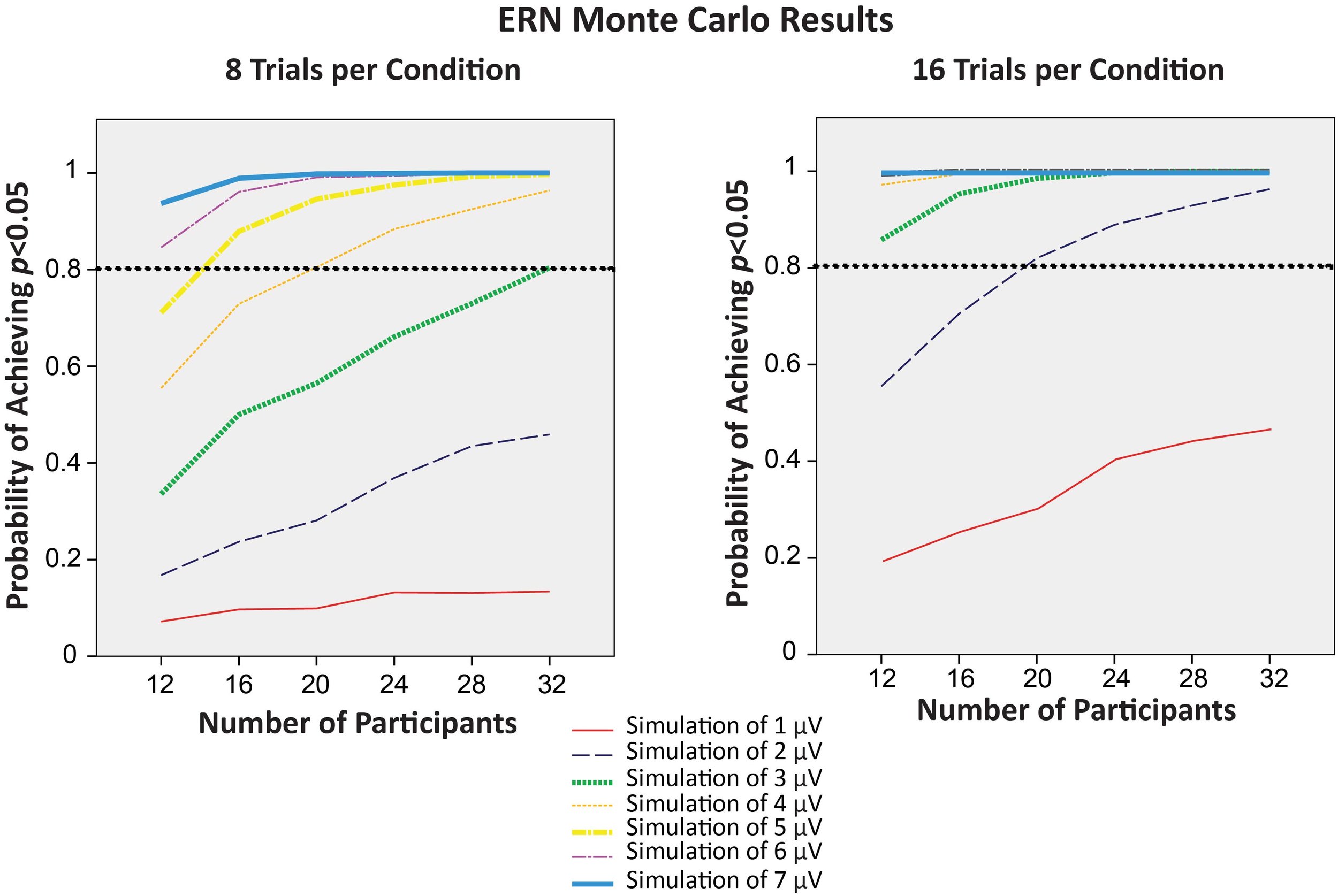
In a recent paper published in Psychophysiology in collaboration with Megan Boudewyn, a project scientist at UC Davis, we demonstrated how the number of trials, the number of participants, and the magnitude of the effect interact to influence statistical power (i.e., the probability of obtaining p<.05). One key finding was that doubling the number of trials recommended by previous studies led to more than a doubling of statistical power under many conditions. Interestingly, increasing the number of trials had a bigger effect on statistical power for within-participants comparisons than for between-group analyses.
The results of this study show that a number of factors need to be considered in determining the number of trials needed in a given ERP experiment, and that there is no magic number of trials that can yield high statistical power across studies.